[5] THE APPLICATION OF LEARNABLE STRF KERNELS TO THE 2021 FEARLESS STEPS PHASE-03 SAD CHALLENGE
T. Vuong, Y. Xia, R.M. Stern, “The Application of Learnable STRF Kernels to the 2021 Fearless Steps Phase-03 SAD Challenge,” Accepted INTERSPEECH, September 2021, Brno, Czechia
[4] GENERALIZED SPOOFING DETECTION INSPIRED FROM AUDIO GENERATION ARTIFACTS
Y. Gao, Tyler Vuong, M. Elyasi, G. Bharaj, R. Singh, “Generalized Spoofing Detection Inspired from Audio Generation Artifacts,” Accepted INTERSPEECH, September 2021, Brno, Czechia
[3] A MODULATION-DOMAIN LOSS FOR NEURAL-NETWORK-BASED REAL-TIME SPEECH ENHANCEMENT
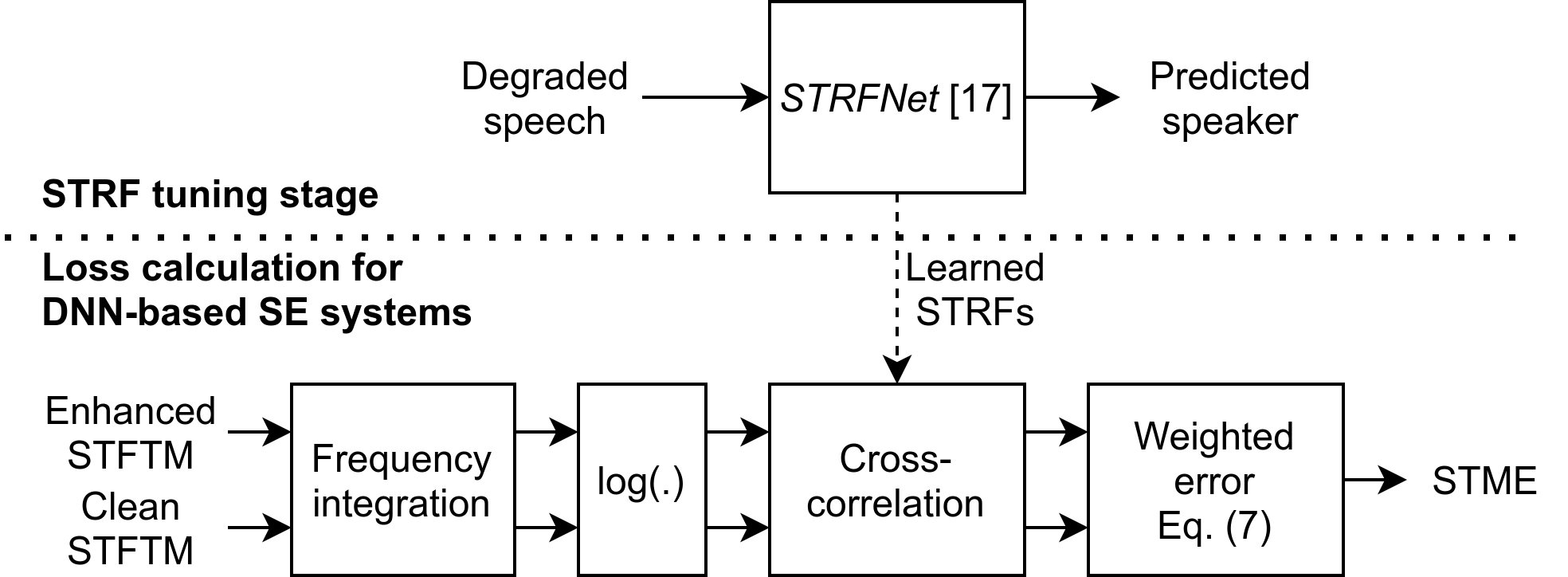
T. Vuong, Y. Xia, R.M. Stern, “A Modulation-Domain Loss for Neural-Network-based Real-time Speech Enhancement,” IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), May 2021, Toronto, Canada
[paper][arXiv][code][presentation][BibTeX]
[2] LEARNABLE SPECTRO-TEMPORAL RECEPTIVE FIELDS FOR ROBUST VOICE TYPE DISCRIMINATION
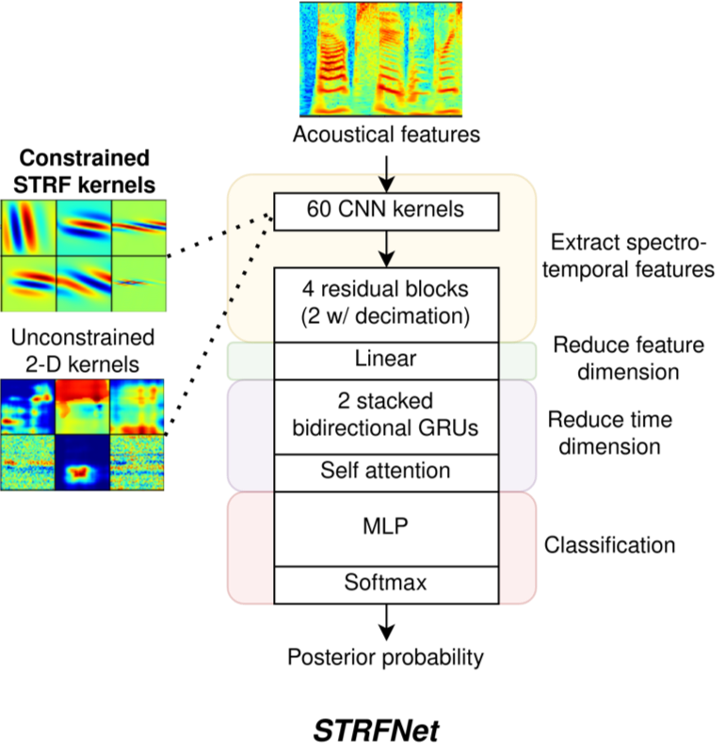
T. Vuong, Y. Xia, R.M. Stern, “Learnable Spectro-temporal Receptive Fields for Robust Voice Type Discrimination,” INTERSPEECH, October 2020, Shanghai, China
[paper][arXiv][code][presentation][BibTeX]
[1] Exploring the Best Loss Function for DNN-Based Low-latency Speech Enhancement with Temporal Convolutional Networks

4th Place on the non-real-time track on the Interspeech 2020 Deep Noise Surpression Challenge
Y. Koyama, T. Vuong, S. Uhlich, and B. Raj, “Exploring the best loss function for DNN-based lowlatency speech enhancement with temporal convolutional networks,” arXiv preprint arXiv:2005.11611, 2020.